
寀ーで WordPressに移転する
寀ーで WordPressに移転したい場合、Pythonでプログラムを作成進めることができます。 他の方法で WordPress オートマチック Pluginを使用すると、簡単に前のが可能です。 このプラグインを利用する方法については、別の記事で取り上げてみましょう。 寀ーに文を作成し WordPressで、その記事の内容を取得して編集して再発行する用途にも良いようです。
※履歴バックアップ機能が再び有効になりました。 これで、ティーストーリーバックアップ機能を使用してティーストーリーデータをバックアップできます。
✅ティーストーリーバックアップファイルを利用して WordPressに移動する (2023年7月更新)
寀ーで WordPressに移転する
下の文は長い時間前に作成されており、今も機能しているかどうかはわかりません。 見つけ見ればより良いプログラムもあります。
どんな方のPythonで WordPressに移転するためのコードを作成してあげたことがありますね。 WordPressに移転したい方は、次の記事を参照して、以前のを試してみてください。
リンクされた文の指示通り沿いしたときにエラーが発生した場合、次の文を参照してください。
この方法を利用するには、Pythonのために少しの知識が必要です。 私VultrにLinuxとPythonをインストールして進行するので、データや画像を抽出することができました。 抽出したデータを利用すれば、簡単に WordPressへの移行が可能です。
下記の内容は、有料プログラムを使用して、データだけを抽出する方法であるため、あまり好ましくありません。
寀ーは2016年12月からのバックアップを停止しました。 したがって、それ以前にバックアップを取る置かなかった場合、新たにバックアップを行うことができません。
しかし、寀ーバックアップに関連して研究をして、最初から方法がないわけではないと思いました。
たとえば、Google SheetsでXPathを使用して、特定のURLのデータを抽出することができます。
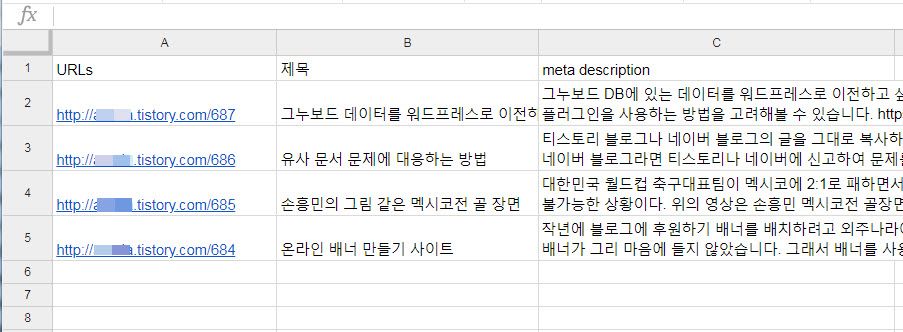
上記の図のようにURLアドレスを受け取って、タイトルなどを抽出することができます。 しかし、問題は、本文の内容をHTMLタグに抽出するには、スクリプトを作成することです。
もしかしたら、このような機能を提供するプログラムがないか検索してからScreaming Frog SEO Spiderと呼ばれるプログラムを発見した。 ウェブサイトのデータの抽出と関連して、有名なプログラムです。
寀ーサイトで本文の内容をHTMLタグをそのまま維持したまま抽出することができるか問い合わせてみると可能である返信を受け取った。
Yes、it is possible to use to the tool as a web scraper。
このようなツールをWeb Scraper(ウェブスクレイパー)とね。
問題は、Webスクレイパー機能を使用するには、有料版を購入する必要があり、コストが少なくありません。 有料版は149ポンドでハンファで22万ウォン程度ですね。
このツールを使用すると、サイトのアドレスだけを持っているサイト内のURLを抽出し、データを任意の方法で整理して、ファイルにすることができるようになります。 詳しい使用方法は、以下のリンクを参照してみてください。
- http://www.seerinteractive.com/blog/screaming-frog-guide/
費用のために個人が購入して使用するには困難があるようです。 ぜひ寀ーだけでなく、ウェブサイトのデータ抽出をするプログラムを希望する場合は、このツールを考慮してみることができます。 ただし、購入する前に必要な機能をしていること販売者に連絡して確認してみるのが安全でしょう。
※ 免責事項:Screaming Frog SEO Spiderを使用して、実際に必要な方法で寀ーブログからデータを抽出することができるかどうかについては、何の保証をしません。 一つの可能性を提示したものだけで、プログラム販売の言葉可能とします。 しかし、他の要因のためにできない場合もありますので、購入を検討している場合は、慎重に考えてください。
寀ーブログのURL、記事のタイトル、カテゴリ、、本文の内容を抽出してcsvファイルやxmlファイルに変換することができている場合 WordPressにどのような方法移転することができます。 たとえば、次のようなプラグインを使用することができます。
- https://wordpress.org/plugins/wp-all-import/
寀ーコメントの場合、以前のことが容易ではないと思われるが、精巧にデータを抽出することができれば可能かもしれません。
直接データ抽出プログラムを作成したい場合は、次の記事が参考になりそうです。
ちなみにXE /ゼロボードで WordPress 移行する方法は「XEで WordPressへ移行する「を参照してください。XE /ゼロボード掲示板から WordPress KBoard 掲示板に移転する作業が必要な場合 ここでサービス(有料)を依頼することができます。
:XEで WordPress 掲示板で簡単移転することができるプラグインをCosmosfarmで開発して販売しています。 プラグインを使用すると、時間とコストを削減することができます。

スクリプトを作成した方がいらっしゃいますね。
https://gist.github.com/taylor224/5eef306afaef7a7a136c66daecba6e41
エラーが発生した場合、次の文を参照してみてください。
http://avada.tistory.com/796
スクリプトを作成した方がいらっしゃいますね。
https://gist.github.com/taylor224/5eef306afaef7a7a136c66daecba6e41
私寀ーバックアップ終了になるし、悩んだ末 WordPressを開始しました。
おそらく一番上手ことの一つだとでしょう。
すべてのファイルは、バックアップが一番重要だこれ終了になると、後ですごく困難らしく、あらかじめ脱退して移動しました。^^
バックアップ終了するバックアップされて出てきた場合は、比較的簡単に、以前は可能だったが、今では、バックアップ自体がないので WordPress などで移転するのが容易ではない状況です。
クルリアンである方が、Pythonで成功されたという記事を見たことがあります。 非常に不可能ではないないようです。
はい、本文にリンクされた「Introduction to web scraping with Python(Pythonを使用したWebスクレイピングの紹介)」の記事では、Pythonを利用してWebサイトのコンテンツを抽出する基本的な方法が紹介されています。 深く勉強すれば十分可能です。
こんにちはこのように抽出をすると、画像は別々に再アップロードをするか?
どうせ22万ウォン出してはいないハゲトジ万気し、良い情報とお問い合わせください^^
こんにちは?
ブログを訪問していただきありがとうございます。
上記の方法でコンテンツを抽出することができます。 本文の場合htmlファイルとして抽出するため、寀ーサーバー(正確な表現かはわかりません)に保存されている画像のリンクとしてのコンテンツを抽出することができます。
本文のHTMLコード部分 WordPress 本文にそのまま入れると、画像が表示されるようです。 しかし、時間を割いて、画像をダウンロードして再アップロードしてくれる仕事をすることが、長期的には望ましくないかと考えられますね。
ちなみにたまにトラフィックを節約するため寀ーに画像を上げて、そのリンクを利用して WordPressで画像を表示する方をご覧ください。 通常は問題ありませんが、SSL証明書をインストールすると、ティーストーリーイメージのために「緑色のロック」が表示されない問題が発生する可能性があります。
はい、私は今ちょうどその状況ですssl認証を受けて手作業でいますㅠもしところがティスとき無にGoogleで同様の文書として認識ドゥェヌではないか(seoに合わせて導入ブッダの基本的な部分は修正が主な内容は、寀ーまま)お問い合わせください。
寀ーを運営しながら、同時に、同じコンテンツに WordPress サイトを運営する場合 WordPress サイトが重複して認識されます。
この場合、301リダイレクトを設定して、サイトが変更されたこと伝える必要がありますが、寀ーは301リダイレクトを設定することができないため、この方法は、ないでしょう。
https://www.thewordcracker.com/intermediate/%EA%B5%AC%EA%B8%80-%EC%88%9C%EC%9C%84%EB%A5%BC-%EC%9C%A0%EC%A7%80%ED%95%9C-%EC%B1%84-%EC%9B%8C%EB%93%9C%ED%94%84%EB%A0%88%EC%8A%A4-%EC%82%AC%EC%9D%B4%ED%8A%B8-%EC%A3%BC%EC%86%8C-%EB%B3%80%EA%B2%BD/
個人的な考えですが。 寀ーブログ記事を非公開に転換し、 NaverとGoogleからURL削除リクエストをしてくれれば、既存寀ー文が検索エンジンから削除されます。
時間が経てば、新しいサイトの記事が正常に検出されないかと思いますね。
寀ーブログを維持しなければならなら、グーグルだけnoindex、nofollowメタタグを追加する方法も考えてみることができるようになります。 (検索から除外させてくれるかどうかは、Googleで判断することです。)
<meta name="googlebot" content="noindex,nofollow">ちなみに画像ファイルが多すぎると、画像ファイルをすべてダウンロードした後、FTP経由で特定のフォルダを作成し、すべてアップロードした後にDBから一括して寀ー画像のURLを変更する方法を検討してみることができるようになります。 その後、多くの時間を節約になります。 画像は、いくつかの空白の場合は、手作業で変えてもドゥェゴヨ。